本文共 14137 字,大约阅读时间需要 47 分钟。
ForkJoinPool 是JDK 7加入的一个线程池类。Fork/Join 技术是分治算法(Divide-and-Conquer)的并行实现,它是一项可以获得良好的并行性能的简单且高效的设计技术。目的是为了帮助我们更好地利用多处理器带来的好处,使用所有可用的运算能力来提升应用的性能
就是在必要的情况下,将一个大任务,进行拆分(fork)成若干个小任务(拆到不可再拆时),再将一个个的小任务运算的结果进行 join 汇总。
JoinFork/Join 框架与线程池的区别
采用 “工作窃取”模式(work-stealing): 当执行新的任务时它可以将其拆分分成更小的任务执行,并将小任务加到线程队列中,然后再从一个随机线程的队列中偷一个并把它放在自己的队列中。 相对于一般的线程池实现, fork/join框架的优势体现在对其中包含的任务的处理方式上.在一般的线程池中, 如果一个线程正在执行的任务由于某些原因无法继续运行, 那么该线程会处于等待状态。 而在fork/join框架实现中,如果某个子问题由于等待另外一个子问题的完成而无法继续运行。 那么处理该子问题的线程会主动寻找其他尚未运行的子问题来执行.这种方式减少了线程的等待时间, 提高了性能。学习之前先来一段代码辅助理解public class TestForkJoinPool { public static void main(String[] args) { Instant start = Instant.now(); ForkJoinPool pool = new ForkJoinPool(); ForkJoinTask task = new ForkJoinSumCalculate(0L, 50000000000L); Long sum = pool.invoke(task); System.out.println(sum); Instant end = Instant.now(); System.out.println("耗费时间为:" + Duration.between(start, end).toMillis());//166-1996-10590 }}class ForkJoinSumCalculate extends RecursiveTask { private static final long serialVersionUID = -259195479995561737L; private long start; private long end; private static final long THURSHOLD = 10000L; //临界值 public ForkJoinSumCalculate(long start, long end) { this.start = start; this.end = end; } @Override protected Long compute() { long length = end - start; if (length <= THURSHOLD) { long sum = 0L; for (long i = start; i <= end; i++) { sum += i; } return sum; } else { long middle = (start + end) / 2; ForkJoinSumCalculate left = new ForkJoinSumCalculate(start, middle); left.fork(); //进行拆分,同时压入线程队列 ForkJoinSumCalculate right = new ForkJoinSumCalculate(middle + 1, end); right.fork(); return left.join() + right.join(); } }}
下面详细介绍Fork/Join
带着问题学习
- Fork/Join主要用来解决什么样的问题?
- Fork/Join框架是在哪个JDK版本中引入的?
- Fork/Join框架主要包含哪三个模块? 模块之间的关系是怎么样的?
- ForkJoinPool类继承关系?
- ForkJoinTask抽象类继承关系? 在实际运用中,我们一般都会继承 RecursiveTask 、RecursiveAction 或 CountedCompleter 来实现我们的业务需求,而不会直接继承 ForkJoinTask 类。
- 整个Fork/Join 框架的执行流程/运行机制是怎么样的?
- 具体阐述Fork/Join的分治思想和work-stealing 实现方式?
- 有哪些JDK源码中使用了Fork/Join思想?
- 如何使用Executors工具类创建ForkJoinPool?
- 写一个例子: 用ForkJoin方式实现1+2+3+...+100000?
- Fork/Join在使用时有哪些注意事项? 结合JDK中的斐波那契数列实例具体说明。
Fork/Join框架简介
Fork/Join框架是Java并发工具包中的一种可以将一个大任务拆分为很多小任务来异步执行的工具,自JDK1.7引入。
三个模块及关系
Fork/Join框架主要包含三个模块:
- 任务对象:
ForkJoinTask(包括RecursiveTask、RecursiveAction和CountedCompleter) - 执行Fork/Join任务的线程:
ForkJoinWorkerThread - 线程池:
ForkJoinPool
这三者的关系是: ForkJoinPool可以通过池中的ForkJoinWorkerThread来处理ForkJoinTask任务。
// from 《A Java Fork/Join Framework》Dong LeaResult solve(Problem problem) { if (problem is small) directly solve problem else { split problem into independent parts fork new subtasks to solve each part join all subtasks compose result from subresults }}
ForkJoinPool 只接收 ForkJoinTask 任务(在实际使用中,也可以接收 Runnable/Callable 任务,但在真正运行时,也会把这些任务封装成 ForkJoinTask 类型的任务),RecursiveTask 是 ForkJoinTask 的子类,是一个可以递归执行的 ForkJoinTask,RecursiveAction 是一个无返回值的 RecursiveTask,CountedCompleter 在任务完成执行后会触发执行一个自定义的钩子函数。
在实际运用中,我们一般都会继承 RecursiveTask 、RecursiveAction 或 CountedCompleter 来实现我们的业务需求,而不会直接继承 ForkJoinTask 类。
核心思想: 分治算法(Divide-and-Conquer)
分治算法(Divide-and-Conquer)把任务递归的拆分为各个子任务,这样可以更好的利用系统资源,尽可能的使用所有可用的计算能力来提升应用性能。首先看一下 Fork/Join 框架的任务运行机制:

核心思想: work-stealing(工作窃取)算法
work-stealing(工作窃取)算法: 线程池内的所有工作线程都尝试找到并执行已经提交的任务,或者是被其他活动任务创建的子任务(如果不存在就阻塞等待)。这种特性使得 ForkJoinPool 在运行多个可以产生子任务的任务,或者是提交的许多小任务时效率更高。尤其是构建异步模型的 ForkJoinPool 时,对不需要合并(join)的事件类型任务也非常适用。
在 ForkJoinPool 中,线程池中每个工作线程(ForkJoinWorkerThread)都对应一个任务队列(WorkQueue),工作线程优先处理来自自身队列的任务(LIFO或FIFO顺序,参数 mode 决定),然后以FIFO的顺序随机窃取其他队列中的任务。
具体思路如下:
- 每个线程都有自己的一个WorkQueue,该工作队列是一个双端队列。
- 队列支持三个功能push、pop、poll
- push/pop只能被队列的所有者线程调用,而poll可以被其他线程调用。
- 划分的子任务调用fork时,都会被push到自己的队列中。
- 默认情况下,工作线程从自己的双端队列获出任务并执行。
- 当自己的队列为空时,线程随机从另一个线程的队列末尾调用poll方法窃取任务。

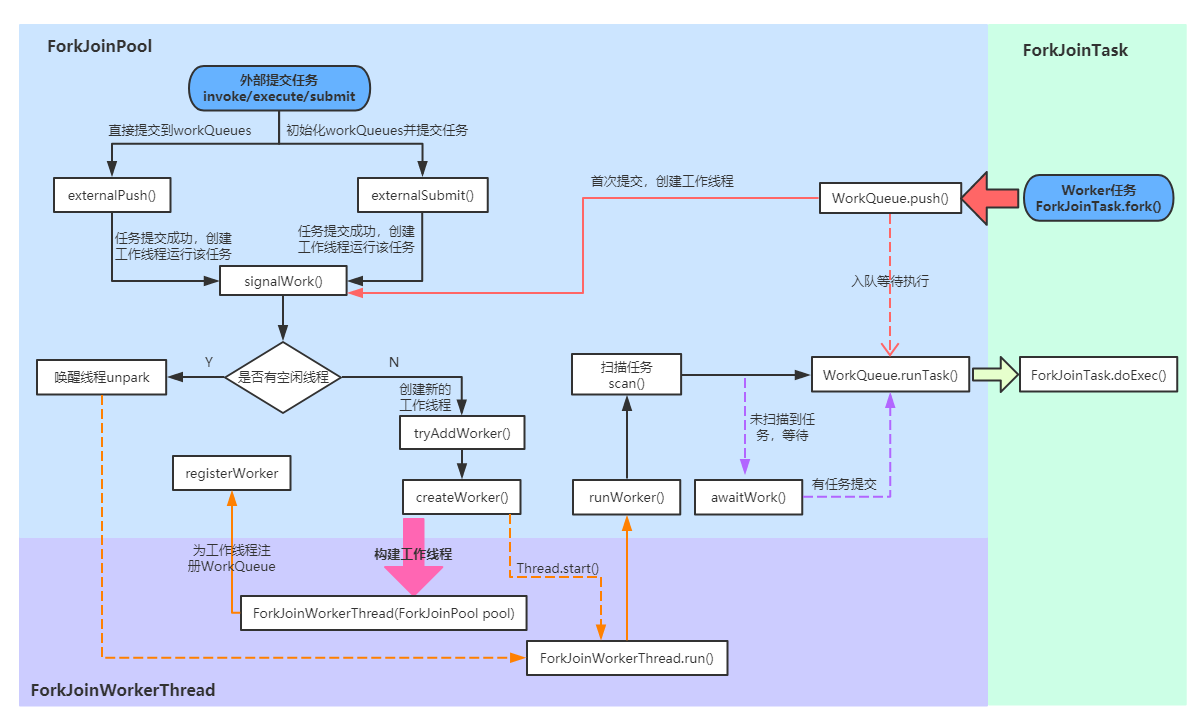
Fork/Join 框架的执行流程
上图可以看出ForkJoinPool 中的任务执行分两种:
- 直接通过 FJP 提交的外部任务(external/submissions task),存放在 workQueues 的偶数槽位;
- 通过内部 fork 分割的子任务(Worker task),存放在 workQueues 的奇数槽位。
那Fork/Join 框架的执行流程是什么样的?
Fork/Join类关系
ForkJoinPool继承关系
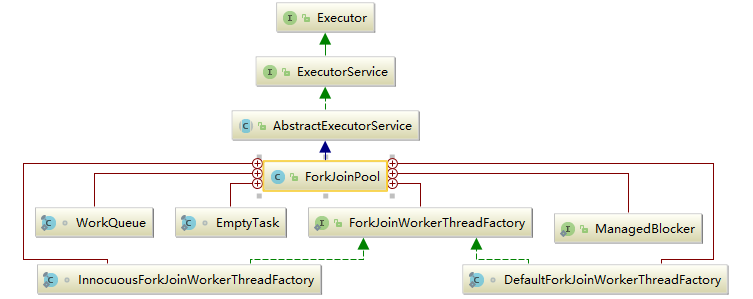
内部类介绍:
-
ForkJoinWorkerThreadFactory: 内部线程工厂接口,用于创建工作线程ForkJoinWorkerThread
-
DefaultForkJoinWorkerThreadFactory: ForkJoinWorkerThreadFactory 的默认实现类
-
InnocuousForkJoinWorkerThreadFactory: 实现了 ForkJoinWorkerThreadFactory,无许可线程工厂,当系统变量中有系统安全管理相关属性时,默认使用这个工厂创建工作线程。
-
EmptyTask: 内部占位类,用于替换队列中 join 的任务。
-
ManagedBlocker: 为 ForkJoinPool 中的任务提供扩展管理并行数的接口,一般用在可能会阻塞的任务(如在 Phaser 中用于等待 phase 到下一个generation)。
-
WorkQueue: ForkJoinPool 的核心数据结构,本质上是work-stealing 模式的双端任务队列,内部存放 ForkJoinTask 对象任务,使用 @Contented 注解修饰防止伪共享。
- 工作线程在运行中产生新的任务(通常是因为调用了 fork())时,此时可以把 WorkQueue 的数据结构视为一个栈,新的任务会放入栈顶(top 位);工作线程在处理自己工作队列的任务时,按照 LIFO 的顺序。
- 工作线程在处理自己的工作队列同时,会尝试窃取一个任务(可能是来自于刚刚提交到 pool 的任务,或是来自于其他工作线程的队列任务),此时可以把 WorkQueue 的数据结构视为一个 FIFO 的队列,窃取的任务位于其他线程的工作队列的队首(base位)。
-
伪共享状态: 缓存系统中是以缓存行(cache line)为单位存储的。缓存行是2的整数幂个连续字节,一般为32-256个字节。最常见的缓存行大小是64个字节。当多线程修改互相独立的变量时,如果这些变量共享同一个缓存行,就会无意中影响彼此的性能,这就是伪共享。
ForkJoinTask继承关系

ForkJoinTask 实现了 Future 接口,说明它也是一个可取消的异步运算任务,实际上ForkJoinTask 是 Future 的轻量级实现,主要用在纯粹是计算的函数式任务或者操作完全独立的对象计算任务。fork 是主运行方法,用于异步执行;而 join 方法在任务结果计算完毕之后才会运行,用来合并或返回计算结果。 其内部类都比较简单,ExceptionNode 是用于存储任务执行期间的异常信息的单向链表;其余四个类是为 Runnable/Callable 任务提供的适配器类,用于把 Runnable/Callable 转化为 ForkJoinTask 类型的任务(因为 ForkJoinPool 只可以运行 ForkJoinTask 类型的任务)。
Fork/Join框架源码解析
分析思路: 在对类层次结构有了解以后,我们先看下内部核心参数,然后分析上述流程图。会分4个部分:
- 首先介绍任务的提交流程 - 外部任务(external/submissions task)提交
- 然后介绍任务的提交流程 - 子任务(Worker task)提交
- 再分析任务的执行过程(ForkJoinWorkerThread.run()到ForkJoinTask.doExec()这一部分);
- 最后介绍任务的结果获取(ForkJoinTask.join()和ForkJoinTask.invoke())
ForkJoinPool
核心参数
在后面的源码解析中,我们会看到大量的位运算,这些位运算都是通过我们接下来介绍的一些常量参数来计算的。
例如,如果要更新活跃线程数,使用公式(UC_MASK & (c + AC_UNIT)) | (SP_MASK & c);c 代表当前 ctl,UC_MASK 和 SP_MASK 分别是高位和低位掩码,AC_UNIT 为活跃线程的增量数,使用(UC_MASK & (c + AC_UNIT))就可以计算出高32位,然后再加上低32位(SP_MASK & c),就拼接成了一个新的ctl。
这些运算的可读性很差,看起来有些复杂。在后面源码解析中有位运算的地方我都会加上注释,大家只需要了解它们的作用即可。
ForkJoinPool 与 内部类 WorkQueue 共享的一些常量:
// Constants shared across ForkJoinPool and WorkQueue// 限定参数static final int SMASK = 0xffff; // 低位掩码,也是最大索引位static final int MAX_CAP = 0x7fff; // 工作线程最大容量static final int EVENMASK = 0xfffe; // 偶数低位掩码static final int SQMASK = 0x007e; // workQueues 数组最多64个槽位// ctl 子域和 WorkQueue.scanState 的掩码和标志位static final int SCANNING = 1; // 标记是否正在运行任务static final int INACTIVE = 1 << 31; // 失活状态 负数static final int SS_SEQ = 1 << 16; // 版本戳,防止ABA问题// ForkJoinPool.config 和 WorkQueue.config 的配置信息标记static final int MODE_MASK = 0xffff << 16; // 模式掩码static final int LIFO_QUEUE = 0; //LIFO队列static final int FIFO_QUEUE = 1 << 16;//FIFO队列static final int SHARED_QUEUE = 1 << 31; // 共享模式队列,负数
ForkJoinPool 中的相关常量和实例字段:
// 低位和高位掩码private static final long SP_MASK = 0xffffffffL;private static final long UC_MASK = ~SP_MASK;// 活跃线程数private static final int AC_SHIFT = 48;private static final long AC_UNIT = 0x0001L << AC_SHIFT; //活跃线程数增量private static final long AC_MASK = 0xffffL << AC_SHIFT; //活跃线程数掩码// 工作线程数private static final int TC_SHIFT = 32;private static final long TC_UNIT = 0x0001L << TC_SHIFT; //工作线程数增量private static final long TC_MASK = 0xffffL << TC_SHIFT; //掩码private static final long ADD_WORKER = 0x0001L << (TC_SHIFT + 15); // 创建工作线程标志// 池状态private static final int RSLOCK = 1;private static final int RSIGNAL = 1 << 1;private static final int STARTED = 1 << 2;private static final int STOP = 1 << 29;private static final int TERMINATED = 1 << 30;private static final int SHUTDOWN = 1 << 31;// 实例字段volatile long ctl; // 主控制参数volatile int runState; // 运行状态锁final int config; // 并行度|模式int indexSeed; // 用于生成工作线程索引volatile WorkQueue[] workQueues; // 主对象注册信息,workQueuefinal ForkJoinWorkerThreadFactory factory;// 线程工厂final UncaughtExceptionHandler ueh; // 每个工作线程的异常信息final String workerNamePrefix; // 用于创建工作线程的名称volatile AtomicLong stealCounter; // 偷取任务总数,也可作为同步监视器/** 静态初始化字段 *///线程工厂public static final ForkJoinWorkerThreadFactory defaultForkJoinWorkerThreadFactory;//启动或杀死线程的方法调用者的权限private static final RuntimePermission modifyThreadPermission;// 公共静态poolstatic final ForkJoinPool common;//并行度,对应内部common池static final int commonParallelism;//备用线程数,在tryCompensate中使用private static int commonMaxSpares;//创建workerNamePrefix(工作线程名称前缀)时的序号private static int poolNumberSequence;//线程阻塞等待新的任务的超时值(以纳秒为单位),默认2秒private static final long IDLE_TIMEOUT = 2000L * 1000L * 1000L; // 2sec//空闲超时时间,防止timer未命中private static final long TIMEOUT_SLOP = 20L * 1000L * 1000L; // 20ms//默认备用线程数private static final int DEFAULT_COMMON_MAX_SPARES = 256;//阻塞前自旋的次数,用在在awaitRunStateLock和awaitWork中private static final int SPINS = 0;//indexSeed的增量private static final int SEED_INCREMENT = 0x9e3779b9;
说明: ForkJoinPool 的内部状态都是通过一个64位的 long 型 变量ctl来存储,它由四个16位的子域组成:
- AC: 正在运行工作线程数减去目标并行度,高16位
- TC: 总工作线程数减去目标并行度,中高16位
- SS: 栈顶等待线程的版本计数和状态,中低16位
- ID: 栈顶 WorkQueue 在池中的索引(poolIndex),低16位
在后面的源码解析中,某些地方也提取了ctl的低32位(sp=(int)ctl)来检查工作线程状态,例如,当sp不为0时说明当前还有空闲工作线程。
ForkJoinPool.WorkQueue 中的相关属性:
//初始队列容量,2的幂static final int INITIAL_QUEUE_CAPACITY = 1 << 13;//最大队列容量static final int MAXIMUM_QUEUE_CAPACITY = 1 << 26; // 64M// 实例字段volatile int scanState; // Woker状态, <0: inactive; odd:scanningint stackPred; // 记录前一个栈顶的ctlint nsteals; // 偷取任务数int hint; // 记录偷取者索引,初始为随机索引int config; // 池索引和模式volatile int qlock; // 1: locked, < 0: terminate; else 0volatile int base; //下一个poll操作的索引(栈底/队列头)int top; // 下一个push操作的索引(栈顶/队列尾)ForkJoinTask [] array; // 任务数组final ForkJoinPool pool; // the containing pool (may be null)final ForkJoinWorkerThread owner; // 当前工作队列的工作线程,共享模式下为nullvolatile Thread parker; // 调用park阻塞期间为owner,其他情况为nullvolatile ForkJoinTask currentJoin; // 记录被join过来的任务volatile ForkJoinTask currentSteal; // 记录从其他工作队列偷取过来的任务
ForkJoinTask
核心参数
/** 任务运行状态 */volatile int status; // 任务运行状态static final int DONE_MASK = 0xf0000000; // 任务完成状态标志位static final int NORMAL = 0xf0000000; // must be negativestatic final int CANCELLED = 0xc0000000; // must be < NORMALstatic final int EXCEPTIONAL = 0x80000000; // must be < CANCELLEDstatic final int SIGNAL = 0x00010000; // must be >= 1 << 16 等待信号static final int SMASK = 0x0000ffff; // 低位掩码
Fork/Join框架源码解析
public ForkJoinPool(int parallelism, ForkJoinWorkerThreadFactory factory, UncaughtExceptionHandler handler, boolean asyncMode) { this(checkParallelism(parallelism), checkFactory(factory), handler, asyncMode ? FIFO_QUEUE : LIFO_QUEUE, "ForkJoinPool-" + nextPoolId() + "-worker-"); checkPermission();}
说明: 在 ForkJoinPool 中我们可以自定义四个参数:
- parallelism: 并行度,默认为CPU数,最小为1
- factory: 工作线程工厂;
- handler: 处理工作线程运行任务时的异常情况类,默认为null;
- asyncMode: 是否为异步模式,默认为 false。如果为true,表示子任务的执行遵循 FIFO 顺序并且任务不能被合并(join),这种模式适用于工作线程只运行事件类型的异步任务。
在多数场景使用时,如果没有太强的业务需求,我们一般直接使用 ForkJoinPool 中的common池,在JDK1.8之后提供了ForkJoinPool.commonPool()方法可以直接使用common池,来看一下它的构造:
private static ForkJoinPool makeCommonPool() { int parallelism = -1; ForkJoinWorkerThreadFactory factory = null; UncaughtExceptionHandler handler = null; try { // ignore exceptions in accessing/parsing String pp = System.getProperty ("java.util.concurrent.ForkJoinPool.common.parallelism");//并行度 String fp = System.getProperty ("java.util.concurrent.ForkJoinPool.common.threadFactory");//线程工厂 String hp = System.getProperty ("java.util.concurrent.ForkJoinPool.common.exceptionHandler");//异常处理类 if (pp != null) parallelism = Integer.parseInt(pp); if (fp != null) factory = ((ForkJoinWorkerThreadFactory) ClassLoader. getSystemClassLoader().loadClass(fp).newInstance()); if (hp != null) handler = ((UncaughtExceptionHandler) ClassLoader. getSystemClassLoader().loadClass(hp).newInstance()); } catch (Exception ignore) { } if (factory == null) { if (System.getSecurityManager() == null) factory = defaultForkJoinWorkerThreadFactory; else // use security-managed default factory = new InnocuousForkJoinWorkerThreadFactory(); } if (parallelism < 0 && // default 1 less than #cores (parallelism = Runtime.getRuntime().availableProcessors() - 1) <= 0) parallelism = 1;//默认并行度为1 if (parallelism > MAX_CAP) parallelism = MAX_CAP; return new ForkJoinPool(parallelism, factory, handler, LIFO_QUEUE, "ForkJoinPool.commonPool-worker-");}
使用common pool的优点就是我们可以通过指定系统参数的方式定义“并行度、线程工厂和异常处理类”;并且它使用的是同步模式,也就是说可以支持任务合并(join)。
执行流程 - 外部任务(external/submissions task)提交
向 ForkJoinPool 提交任务有三种方式:
- invoke()会等待任务计算完毕并返回计算结果;
- execute()是直接向池提交一个任务来异步执行,无返回结果;
- submit()也是异步执行,但是会返回提交的任务,在适当的时候可通过task.get()获取执行结果。
这三种提交方式都都是调用externalPush()方法来完成,所以接下来我们将从externalPush()方法开始逐步分析外部任务的执行过程。
externalPush(ForkJoinTask<?> task)
//添加给定任务到submission队列中final void externalPush(ForkJoinTask task) { WorkQueue[] ws; WorkQueue q; int m; int r = ThreadLocalRandom.getProbe();//探针值,用于计算WorkQueue槽位索引 int rs = runState; if ((ws = workQueues) != null && (m = (ws.length - 1)) >= 0 && (q = ws[m & r & SQMASK]) != null && r != 0 && rs > 0 && //获取随机偶数槽位的workQueue U.compareAndSwapInt(q, QLOCK, 0, 1)) {//锁定workQueue ForkJoinTask [] a; int am, n, s; if ((a = q.array) != null && (am = a.length - 1) > (n = (s = q.top) - q.base)) { int j = ((am & s) << ASHIFT) + ABASE;//计算任务索引位置 U.putOrderedObject(a, j, task);//任务入列 U.putOrderedInt(q, QTOP, s + 1);//更新push slot U.putIntVolatile(q, QLOCK, 0);//解除锁定 if (n <= 1) signalWork(ws, q);//任务数小于1时尝试创建或激活一个工作线程 return; } U.compareAndSwapInt(q, QLOCK, 1, 0);//解除锁定 } externalSubmit(task);//初始化workQueues及相关属性}
转载地址:http://rhxzb.baihongyu.com/